Observability & Monitoring for AI Agents
The Nevermined Payment Libraries include built-in observability capabilities that allow you to monitor, track, and analyze your AI agent’s performance, usage patterns, and costs. This integration provides comprehensive logging and analytics for your AI operations.Overview
The observability API provides:- Request/Response Logging: Automatic logging of all AI API calls with full context
- Usage Tracking: Token usage, costs, and performance metrics
- Custom Properties: Add custom metadata to your logs for better analysis
- Real-time Monitoring: View logs and metrics in the Nevermined dashboard
Basic Integration
1. Initialize the Observability API
The observability functionality is automatically available through thePayments class:
- TypeScript
- Python
2. Configure OpenAI with Observability Logging
Use thewithOpenAI method to wrap your OpenAI client with automatic logging:
- TypeScript
- Python
3. Configure Langchain with Observability Logging
Use thewithLangchain method to wrap your Langchain client with automatic logging:
- TypeScript
- Python
Advanced Usage
Manual Operation Logging
Documentation for Manual Operation Logging is coming soon. This section will
cover how to wrap custom operations with observability logging for non-OpenAI
or Langchain services.
Custom Properties and Metadata
Add custom properties to track additional context:- TypeScript
- Python
Usage Calculation Helpers
Documentation for usage calculation helpers for video and audio operations is
coming soon. This section will cover how to calculate usage metrics for
different types of AI operations.
Pricing Simulation
The pricing simulation feature allows you to test and estimate costs without requiring agent registration, plans, or user subscriptions. This is perfect for development, testing, and cost estimation before going to production.- TypeScript
- Python
- No agent or plan registration required
- No user subscriptions needed
- Automatic cost calculation with configurable profit margins
- Full observability tracking included
- Perfect for testing, development, and cost estimation
Batch vs Regular Requests
You can process requests in two modes:- Regular Requests: Process one request at a time. Each request gets its own unique agent request ID.
- Batch Requests: Process multiple requests together using the same agent request ID. This is useful when you need to make multiple AI calls (e.g., multiple OpenAI requests) within a single user request, and you want to redeem credits once at the end for all operations combined.
- TypeScript
- Python
Credit Redemption Strategies
There are two ways to redeem credits after processing a request:Important: The redemption method you use must match how you started the request:
- If you used
startProcessingRequest(), useredeemCreditsFromRequest()orredeemWithMarginFromRequest() - If you used
startProcessingBatchRequest(), useredeemCreditsFromBatchRequest()orredeemWithMarginFromBatchRequest()
Fixed Credit Redemption
Charges a specific number of credits per request. Useful for predictable, pay-per-use models. The credit amount can be a static value or calculated dynamically (e.g., based on token usage, API calls made, or other metrics).- TypeScript
- Python
Margin-based Redemption
Charges the actual API cost plus a margin percentage. Useful for adding a service fee on top of API costs. The margin percentage can be a static value or calculated dynamically (e.g., based on business logic, user tier, or market conditions). For example, if an API call costs 10 cents and you set a 20% margin (0.2), the total charge will be 10 + (10 × 0.2) = 12 cents in dollar-equivalent credits.- TypeScript
- Python
Complete Example
Here’s a complete example showing how to integrate observability into an AI agent:- TypeScript
- Python
Additional Examples
Batch Mode
Batch Mode
Complete example using batch request processing. This example shows making multiple AI calls within a single batch request, all sharing the same agent request ID:
- TypeScript
- Python
Margin-based Pricing
Margin-based Pricing
Complete example using margin-based credit redemption:
- TypeScript
- Python
Batch Mode + Margin-based Pricing
Batch Mode + Margin-based Pricing
Complete example combining batch processing with margin-based pricing. All operations share the same agent request ID, and credits are redeemed once at the end based on actual API costs plus margin:
- TypeScript
- Python
Monitoring and Analytics
Events Log Table
The frontend provides a comprehensive events log table showing: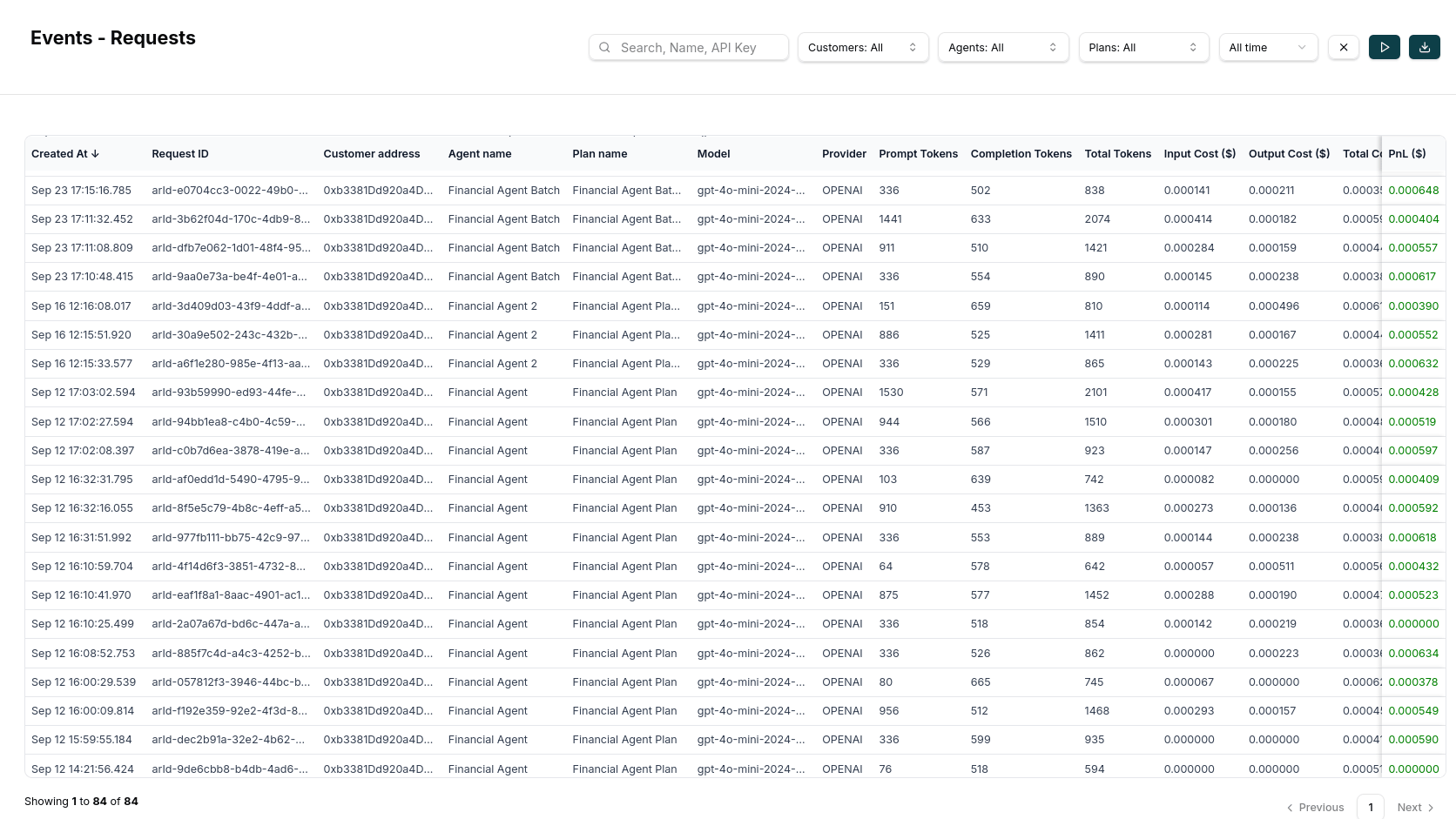
Key Metrics Tracked
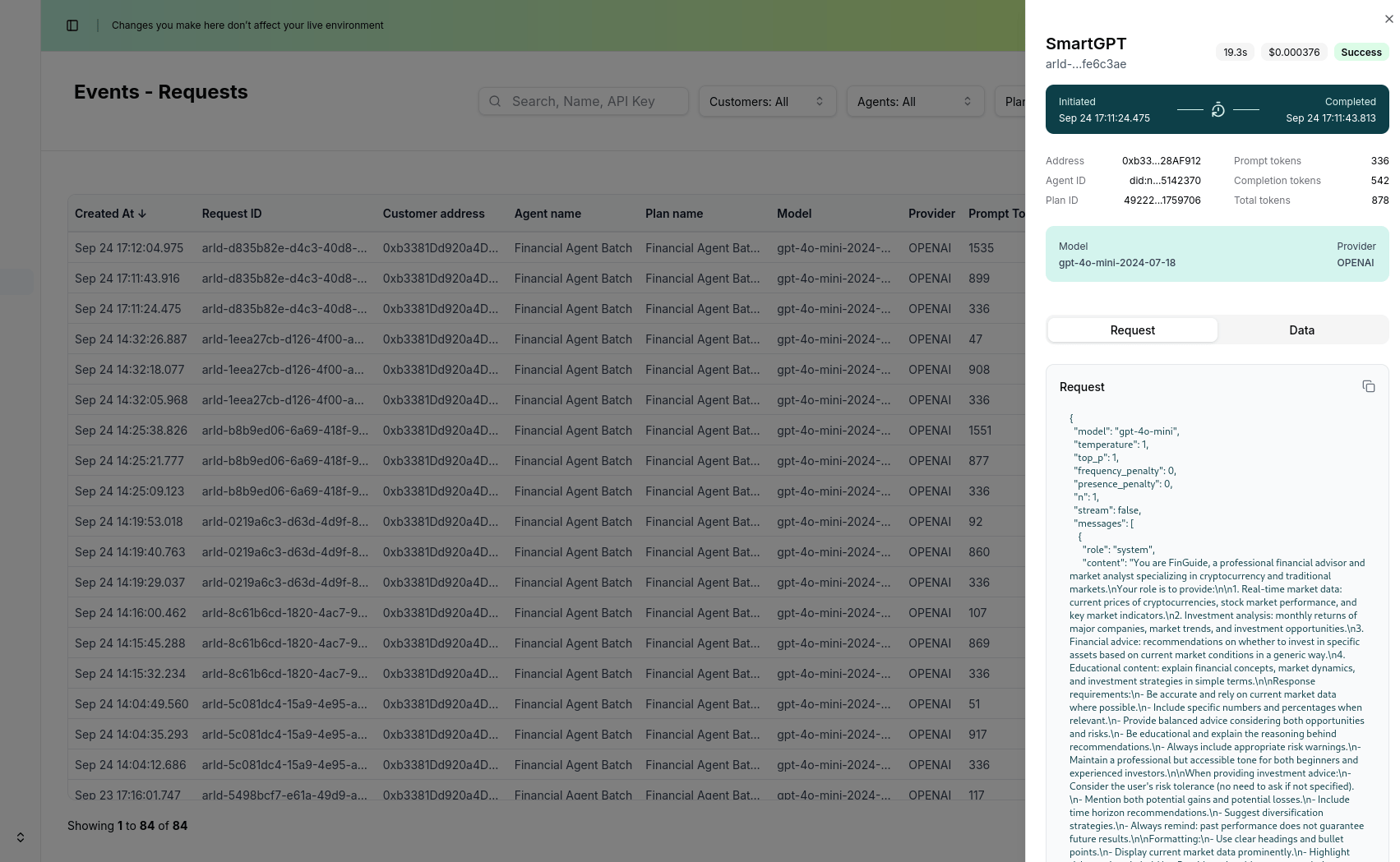
The observability integration automatically tracks:- Timestamp: When each request was made
- User: Account address and session information
- Agent: Agent name and operation type
- Request: Input query and context
- Response: AI-generated response
- Cost Analysis: Credit consumption and cost per request
- Status: Success/failure status
- Performance Metrics: Response times, success rates, error rates, token usage, and more
Data Analytics Dashboard
Once your agent is running with observability enabled, you can view detailed data analytics in the Nevermined dashboard: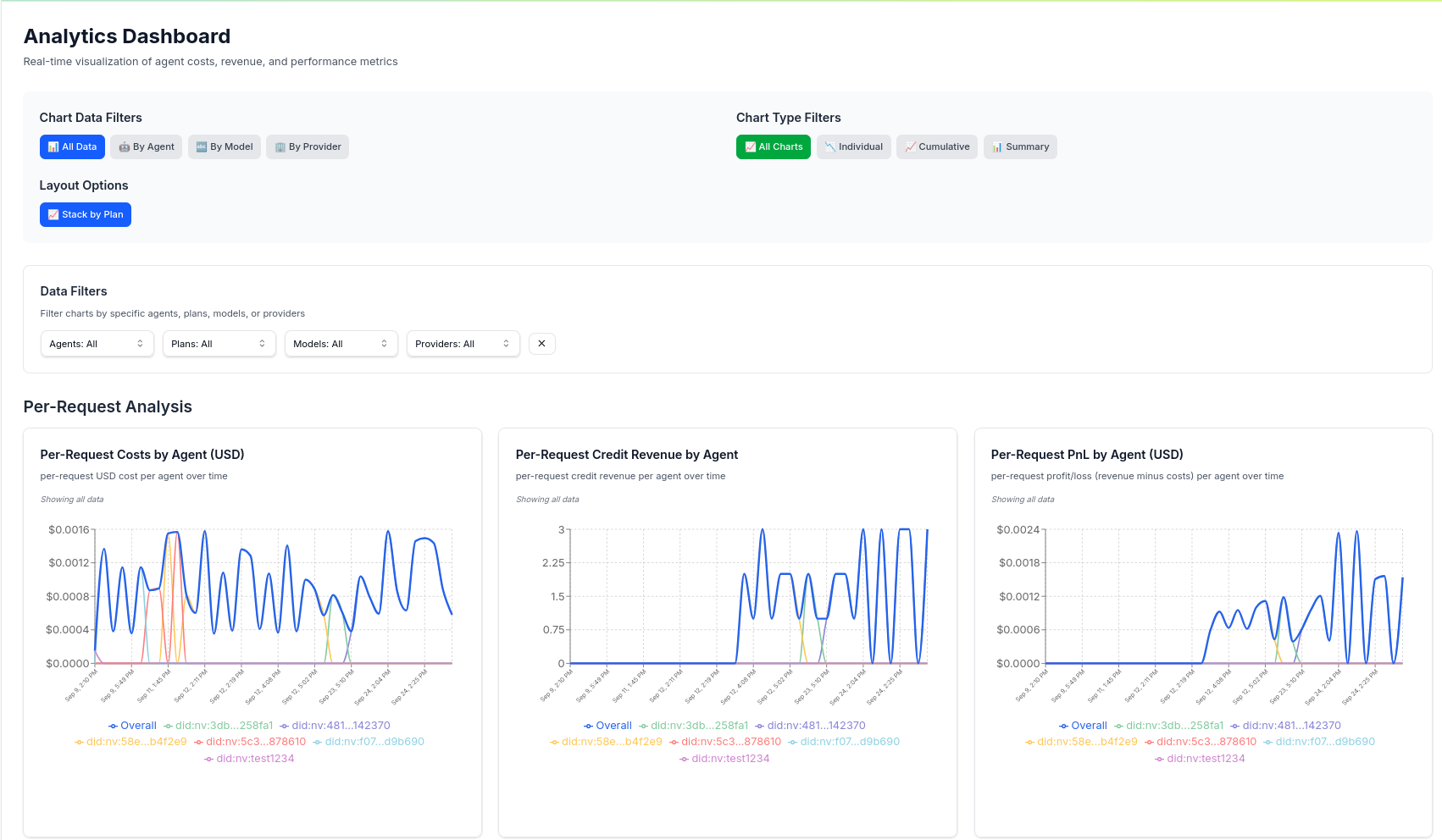
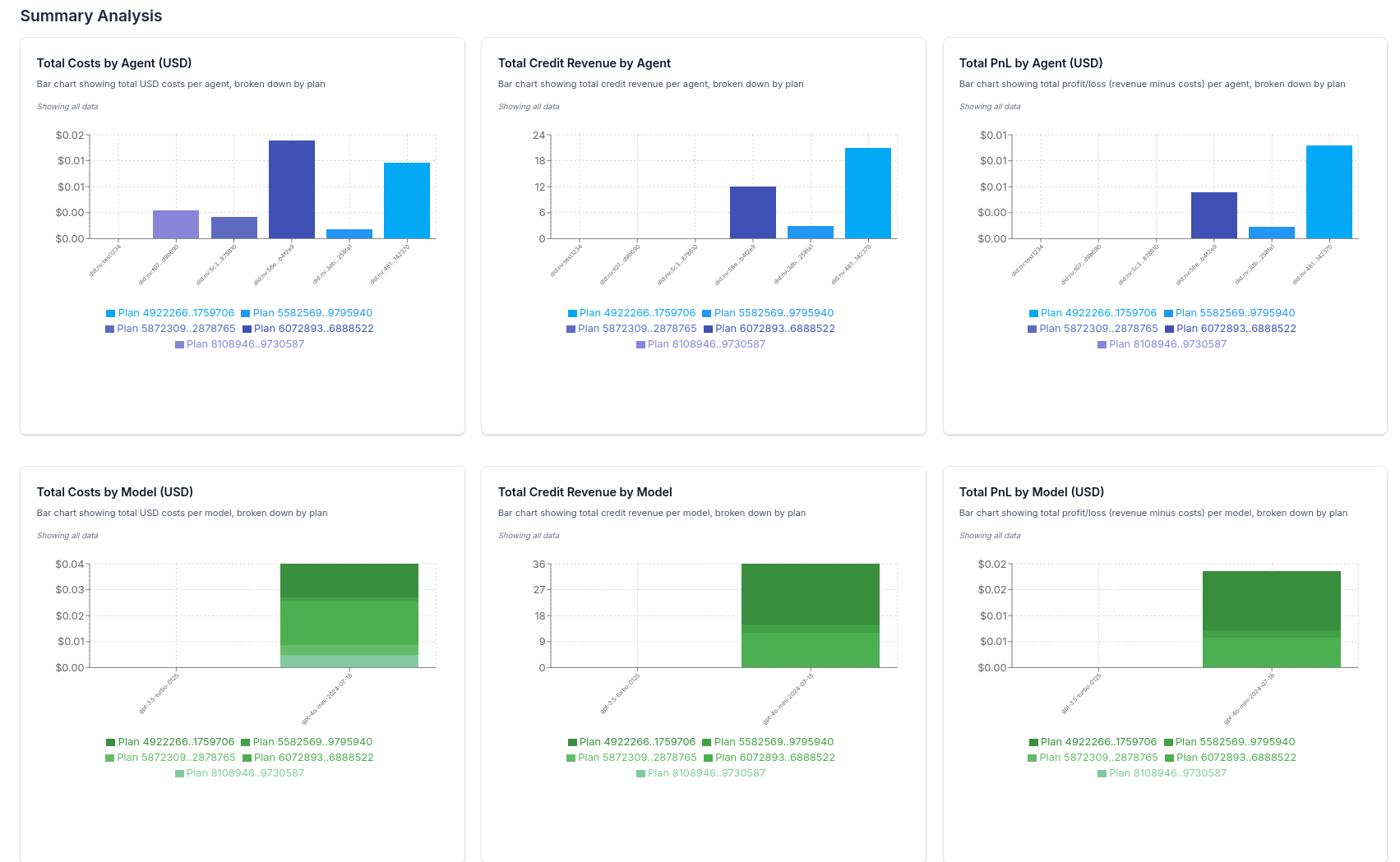
Key Metrics Tracked
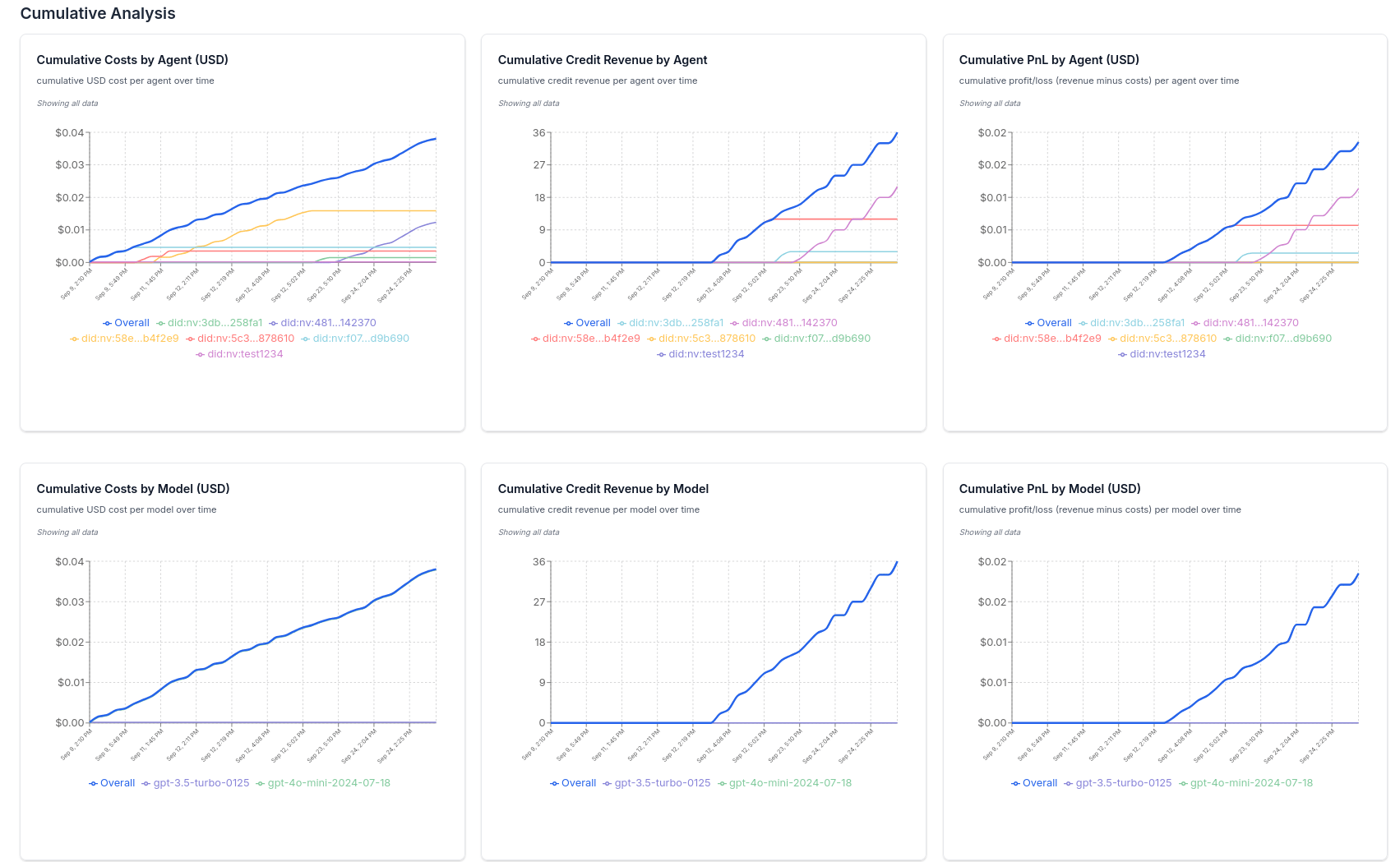
The observability integration automatically tracks:- Per Request Analysis: Cost, credit revenue, PnL, by agent, model, and more
- Cumulative Analysis: Cost, credit revenue, PnL, by agent, model, and more
- Summary Analysis: Cost, credit revenue, PnL, by agent, model, and more
Filtering and Search
Use the built-in filtering capabilities to analyze specific patterns: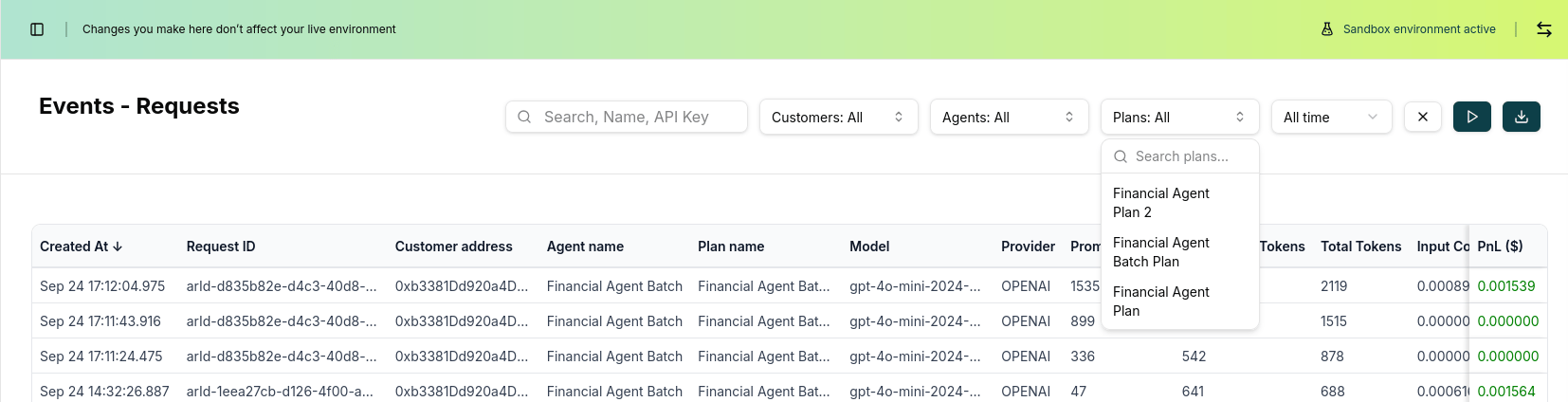
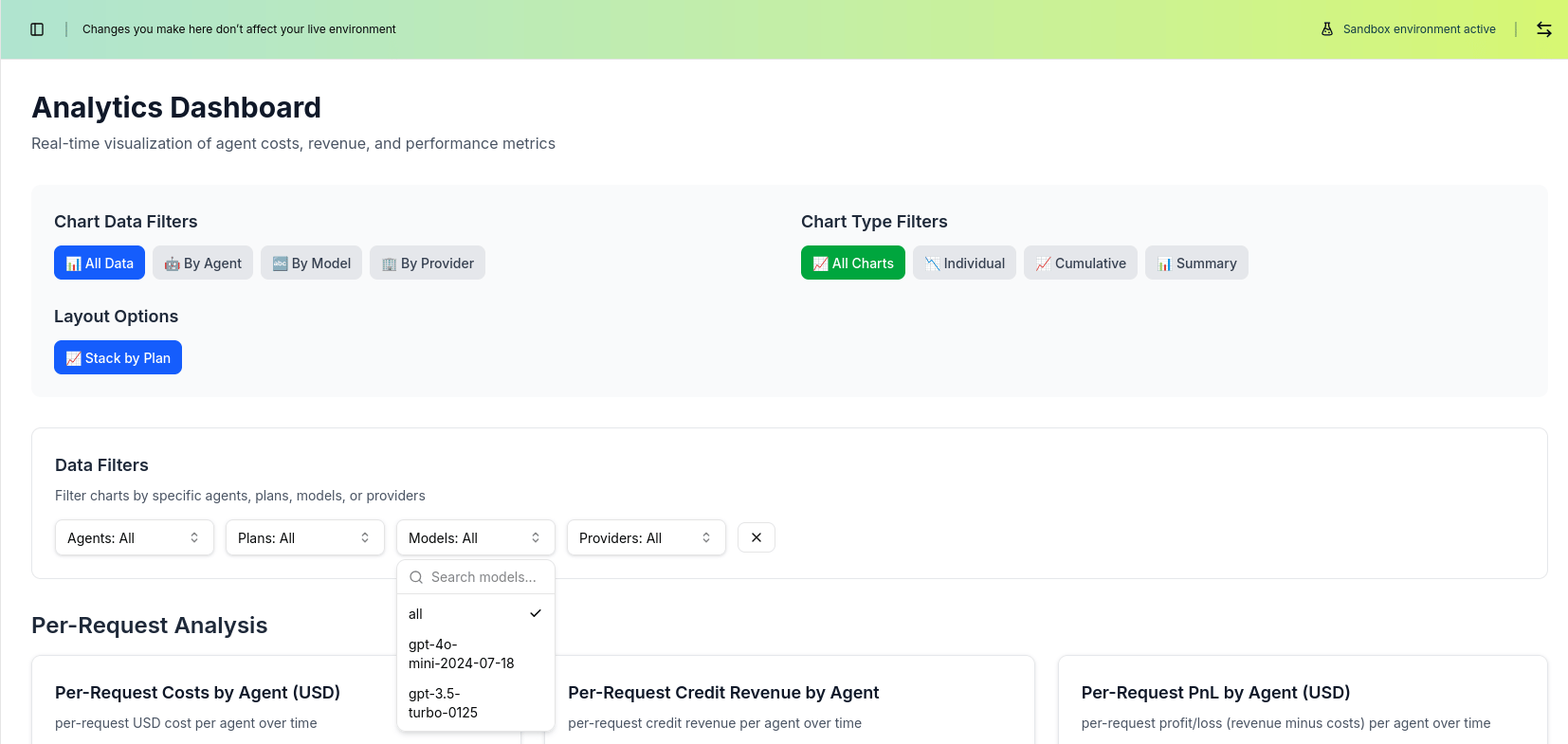
Next Steps
Process Requests
Learn how to handle and validate paid requests in your agents
Query Agents
Learn how to query AI agents programmatically